Flask on AWS Serverless: A learning journey - Part 2
About 3 years ago I learnt some basic Python, which I've used almost exclusively to
In a previous post, we spoke in depth about product/feature teams. In this post, I want to talk about a Platform team, that will support the platform used by the feature teams
In order to scale DevOps, and align the Org structure to business objectives, we create multiple feature teams/tribes, each dedicated to a specific use cases, products or areas, that will deeply understand that context to efficiently deliver for that area.
The Platform team is responsible for:
Product/Feature teams are responsible for using the platform to develop and support specific APIs and microservices for a product. They also responsible for running and operating that particular instance they use. The Platform team is not meant to be building product requirements, unless its a utility.
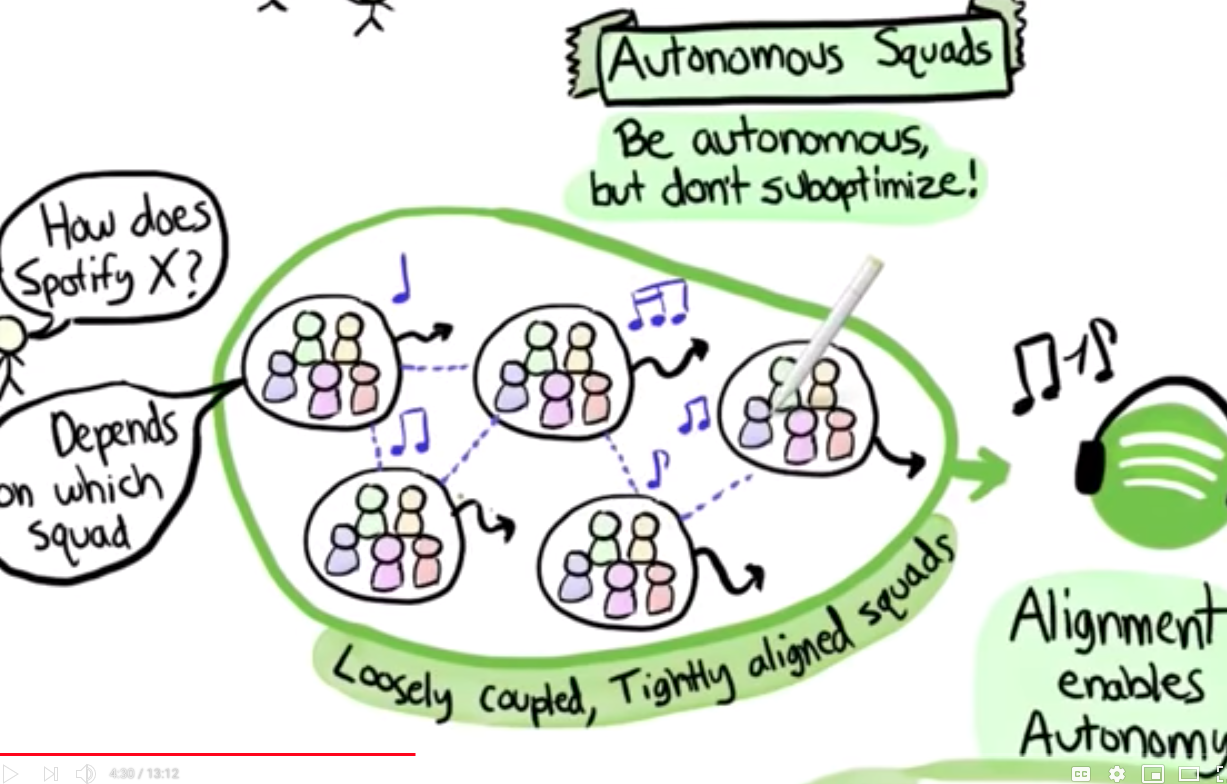
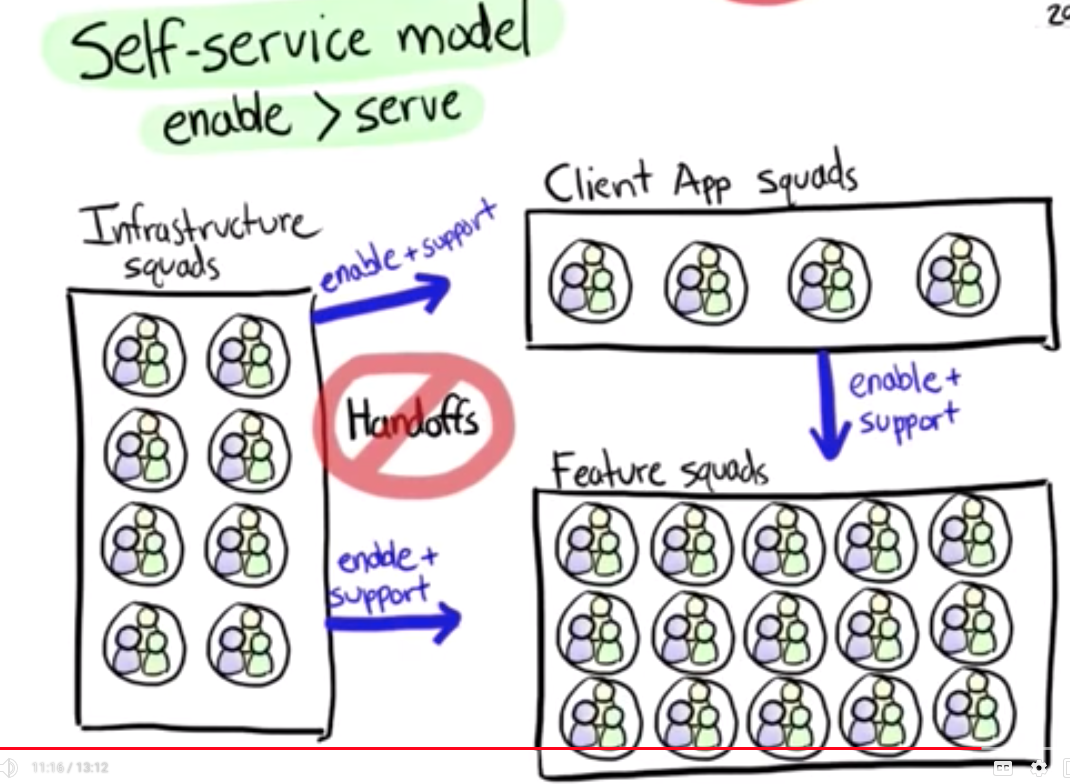
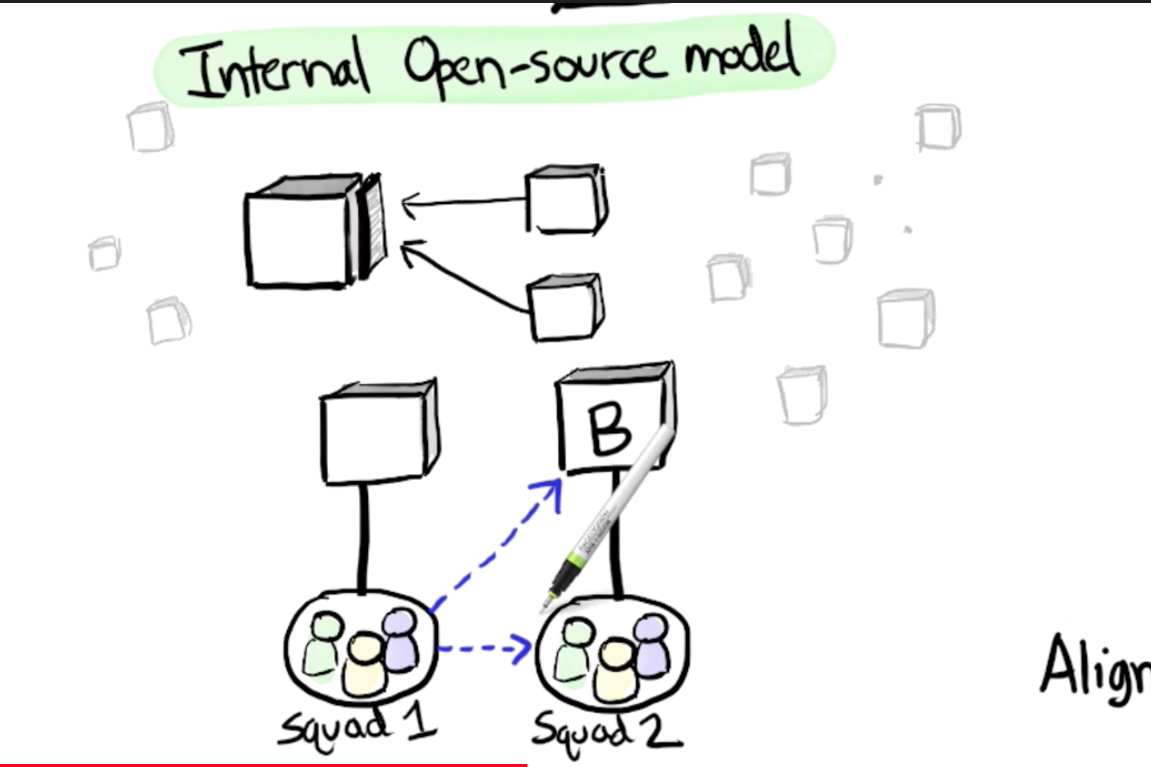
Lets look at the classical Spotify model
At about 4 mins:

At about 10 mins in:

At about 5 mins - based on the Open Source model of code ownership:

Some principles on how to build distributed teams with all the capabilities needed:
In on-premises environments customers often have a central team for technology architecture that acts as an overlay to other product or feature teams to ensure they are following best practice. Technology architecture teams are often composed of a set of roles such as Technical Architect (infrastructure), Solutions Architect (software), Data Architect, Networking Architect, and Security Architect. Often these teams use TOGAF or the Zachman Framework as part of an enterprise architecture capability. At AWS, we prefer to distribute capabilities into teams rather than having a centralized team with that capability. There are risks when you choose to distribute decision making authority, for example, ensuring that teams are meeting internal standards.
We mitigate these risks in two ways:
For architecture this means that we expect every team to have the capability to create architectures and to follow best practices. To help new teams gain these capabilities, or existing teams to raise their bar, we enable access to a virtual community of principal engineers who can review their designs and help them understand what AWS best practices are. The principal engineering community works to make best practices visible and accessible. One way they do this, for example, is through lunchtime talks that focus on applying best practices to real examples. These talks are recorded and can be used as part of onboarding materials for new team members
In the book “DevOps for the Modern Enterprise: Winning Practices to Transform Legacy IT Organizations”, Mirco defines this structure:
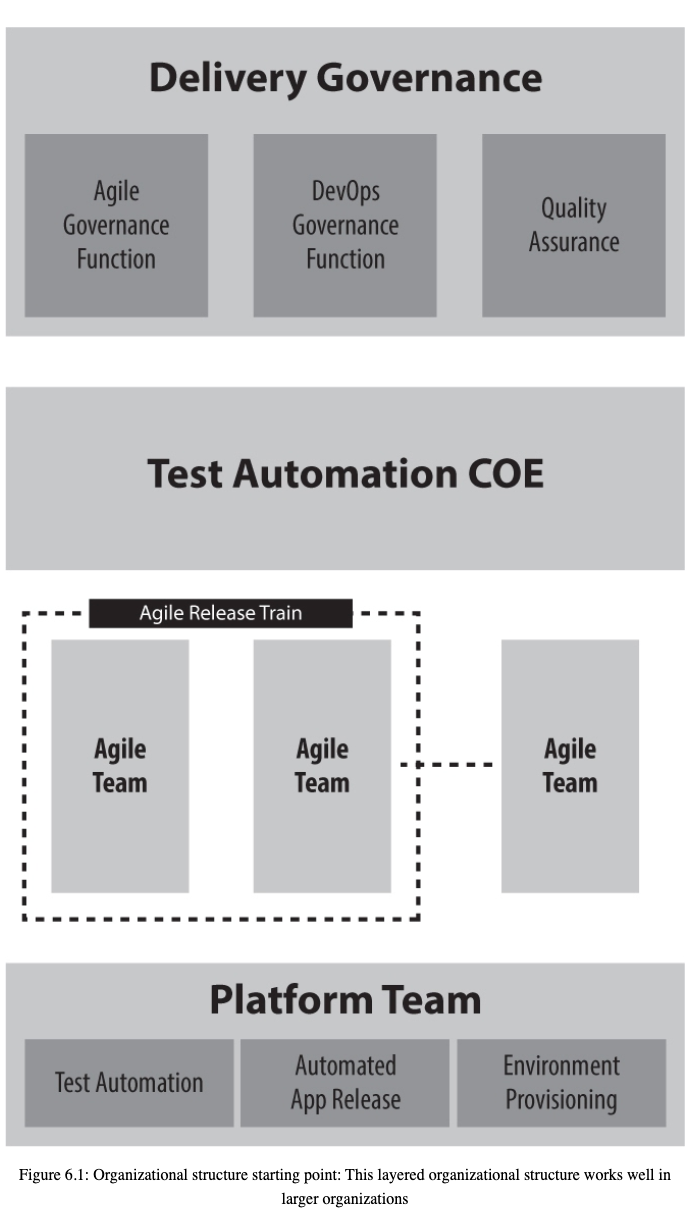

The platform team owns your development and run platform for your applications. In the end-state world, this development and run platform will act like an in-house-platform service provider that provides all your teams with self-service capabilities to support their delivery of solutions. Within this platform team, you will need to have people with skills across the whole set of DevOps capabilities. This means the team needs to cover
As you can see, this is a team of cross-skilled experts, and I would expect some of your best engineers to be part of this team. Many organizations dealing with large legacy systems have structured themselves around technologies (e.g., a Windows team, a UNIX team, an Oracle team). The new platform team will still require some specialized skills for those technologies, but the focus will be a lot more on automation skills and the ability to redefine processes and architectures for the new world. As a result, you should not have technology-specific platform teams.
The challenge I sometimes see with these platform teams is that they perceive themselves as “guardian” of DevOps rather than a service provider, and make it difficult for teams to adopt the platform. It is common to underestimate the level of change management required to make the adoption a success. When the platform is not able to support the teams in a way that makes life easier for teams, then those teams will look for alternatives to the common platform by creating their own custom solutions. A collaborative and flexible approach is required by the platform team to work with the teams they are providing the service for. Their platform should make doing the right thing easier than doing the wrong thing. It is also helpful to have some technical coaches in this team that have the capacity to sit with the teams when problems arise. Alternatively, you can rotate people between feature teams and the platform team or you can loan platform team members to feature teams, as this will help to break down cultural silos that might otherwise appear.
The platform team will evolve over time. When you initially form it, there will likely be many activities that require manual tasks, which means this team will be quite large; but it will shrink as more automation is introduced. To be able to introduce more and more automation over time, you will have to create sufficient capacity in the team to make the required improvements; otherwise, the old saying will become true: “We are too busy to help ourselves improve.”
The accountabilities of the platform team include the following across development, test, and production environments:
You can see that it will take a while until you can see that it will take a while until you have a fully automated delivery platform, and managing the ongoing evolution of the platform team is a crucial aspect of your transformation. I am skeptical that this can be done as a big-bang project, as I have never seen anyone who could find a way around the number of unknowns and the speed of change in tools and technologies that can be leveraged. A structured roadmap and continuous improvement will create the best delivery platform for your organization. The platform team needs to have change-management capability. Technical people tend to assume that once the right tools are in place, everyone will just follow the “right” process. This method usually fails. You need someone who is able to create trainings, run workshops, and deal with the users of the platform to understand the “experience” on the platform.
The Platform team will integrate the test scripts so that the overall pipeline enforces good behavior and makes the results visible. The platform team also works with the test engineers to agree on standards that will make sure the scripts work on the platform (e.g., for environment variables).
It is important to mention that architecture governance needs to be done in close collaboration with the application teams to avoid creating an ivory tower function that is prescribing ideals that are beyond practicality.
The “meat” of the burger is the Agile/Feature teams—where most of the work is being done. For this book, I will ignore the fact that some of the delivery teams will be Waterfall project teams that continue to work in a traditional way (there is a lot of literature out there telling you how to deliver well with traditional teams). Instead, I will highlight the Agile-focused delivery teams, as this route requires changes to your organization. Let’s start by discussing the composition of these teams. A lot has been said about cross-skilled teams and bringing operations people into the teams to achieve DevOps, in effect adding more and more people with specialist skills to an ever-increasing team. For me, just bringing more and more people into the same team is all too simplistic, as it does not scale well in complex environments where many different skills across Dev and Ops are required to achieve an outcome. Rather than bloating the team by adding people, we need to focus teams on building the product and, in this process, consuming services from other teams that are nondifferentiating, like application deployments. The Agile teams should have a product owner, business analysts, a Scrum master, developers, quality engineers, and testers in the proportions that are required to design, build, and test the system. Over time, each team member should build skills across multiple dimensions, aiming for a T-shaped skill profile. † We will let the platform team deal with how the application gets deployed and how the environment needs to look for the application to run well. The Agile teams will collaborate with the platform team, but they don’t need to have a full-time DevOps engineer in their team; when more support is required, a DevOps engineer can be loaned to the Agile team as required, full-time or part-time. Furthermore, in most organizations there will be an external testing team to support later phases of testing. The accountability of the Agile teams is really to get the system into a state that it is as close to releasable as possible. For this to be efficient, the Agile team will use definitions of ready to determine when a user story can be used for delivery and has sufficient detail to become part of the sprint backlog. It uses a definition of done to determine when all activities that can be completed during a sprint/iteration are completed.
From a DevOps perspective, the Agile teams should be responsible not just for delivery of new functionality but also for fixing any production defects or minor changes coming from production. The teams are responsible for the application they are building and are not handing it off to some other “production team” or “fix team.” This changes the incentive for good code and maintainability of the application significantly. This shift in end-to-end responsibility means that Agile teams should be meaningfully aligned to business processes. The best way to do this is by having one or more Agile teams supporting a value stream in your business. Large organizations will need more than one Agile team to support their business value streams, which is where the SAFe concept of release trains comes in to orchestrate and manage a group of Agile teams to support a value stream. ‡ Within this group of Agile teams, the technical composition of those Agile teams requires some consideration.
Martin Fowler says this about platforms, including this from Thoughtworks
The adoption of cloud and DevOps, while increasing the productivity of teams who can now move more quickly with reduced dependency on centralized operations teams and infrastructure, also has constrained teams who lack the skills to self-manage a full application and operations stack. Some organizations have tackled this challenge by creating platform engineering product teams. These teams operate an internal platform which enables delivery teams to self-service deploy and operate systems with reduced lead time and stack complexity. The emphasis here is on API-driven self-service and supporting tools, with delivery teams still responsible for supporting what they deploy onto the platform. Organizations that consider establishing such a platform team should be very cautious not to accidentally create a separate DevOps team, nor should they simply relabel their existing hosting and operations structure as a platform.
What makes a platform compelling? Here are a few ideas:
https://medium.com/adobetech/why-do-organizations-need-a-platform-team-910d79893e0a
By creating a platform team with 259 people, we can have an organization of 1,000 work with the effectiveness of 1,465 people.
In other words, for a larger organization, by having 25% of your engineers working on the platform, you will increase total organization effectiveness.
https://medium.com/adobetech/the-engineering-managers-dilemma-be708ecce8ea
The most common way to build a platform team is to reallocate engineers from existing product teams. Rather than moving 256 engineers all at once, perhaps we start with 10 engineer . The best strategy is to plan ahead. Start growing the platform team when the organization is around 100 engineers. As the company grows, grow the platform team.
https://www.quora.com/What-does-the-Platform-team-do-at-Quora
We’re responsible for creating the tools and building blocks that allow product developers to build the right features quickly
The goal of the product platform team at Quora is to provide tools and abstractions (or building blocks) that allow product engineers to move quickly in their everyday work. As a engineer on this team it is very important to keep this in mind. If I lose sight of the goals for the tools that I'm building, then the abstractions I build might end up not meeting the use-cases of product engineers — or worse, slow them down. In order to set up clear goals, my team-mates and I need a clear understanding of the problems we are solving
Having a semi flat structure with multiple senior and principal engineer that could make agile decision is recommended. Also having a big team like this with many moving parts would mean that a technical lead role is unsuitable rather having a engineering manager for platform and solution architect is essential.
The solution architect could lay out the roadmap of the platform team. Then coordinate that with the rest of the engineering teams. In this process we can also understand the needs of organization. And then plan what capabilities we need. Finally the solution architect can help lead the selection of technologies to add to the platform.
The engineering manager could help with communicating and building out relationships. This is important for number of reasons. First being a true cross functional team the number of request will be high. Second the prioritization of tasks will be crucial in building out capabilities.
https://codingsans.com/blog/managing-platform-teams
There are many ways to structure a platform engineering team. The most basic focus areas are the following:
Ideally, these would be on the mind of every engineer on the team, but people are naturally drawn to different areas, so make sure you have at least one person leading each of those.
https://lightstep.com/blog/how-to-build-a-platform-team/
Some principles on how to build distributed teams with all the capabilities needed: https://aws.amazon.com/architecture/well-architected/
In on-premises environments customers often have a central team for technology architecture that acts as an overlay to other product or feature teams to ensure they are following best practice. Technology architecture teams are often composed of a set of roles such as Technical Architect (infrastructure), Solutions Architect (software), Data Architect, Networking Architect, and Security Architect. Often these teams use TOGAF or the Zachman Framework as part of an enterprise architecture capability. At AWS, we prefer to distribute capabilities into teams rather than having a centralized team with that capability. There are risks when you choose to distribute decision making authority, for example, ensuring that teams are meeting internal standards.
We mitigate these risks in two ways:
For architecture this means that we expect every team to have the capability to create architectures and to follow best practices. To help new teams gain these capabilities, or existing teams to raise their bar, we enable access to a virtual community of principal engineers who can review their designs and help them understand what AWS best practices are. The principal engineering community works to make best practices visible and accessible. One way they do this, for example, is through lunchtime talks that focus on applying best practices to real examples. These talks are recorded and can be used as part of onboarding materials for new team members
Heres another way to look at the DevOps Platform Engineer, https://www.gartner.com/document/code/320951?ref=grbody&refval=3891090
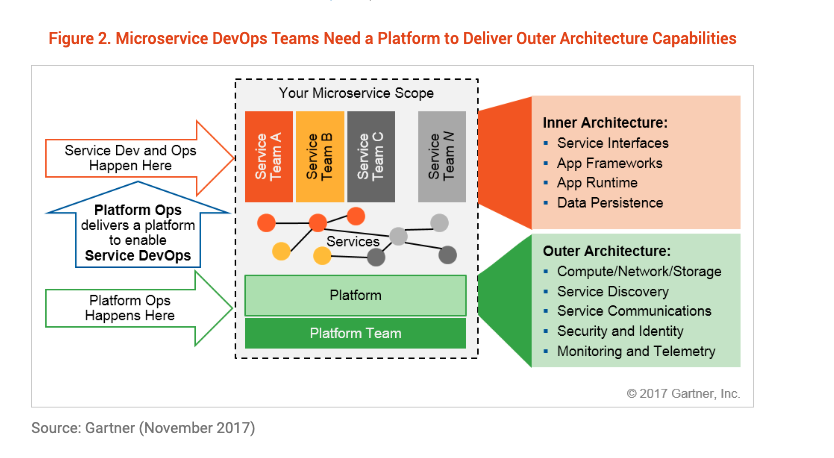
Microservice architecture is intended to speed the delivery of code to production and allow development organizations to scale while remaining nimble. "How to Succeed With Microservice Architecture Using DevOps Practices" describes how part of the successful adoption of microservices involves reorganizing teams to align to microservices rather than platform architecture layers. A microservice team should be accountable for the delivery of the running service, not just writing the code, deploying the code or monitoring the deployed code. This change drives autonomy and accountability for delivering a working service that provides business value. Hence, this team has both Dev and Ops responsibilities; it is a service DevOps team.
However, the operational responsibility in a service DevOps team is focused on the running of the service — "service ops." That same service will run on an infrastructure that must also be deployed, monitored, maintained, scaled and secured. Someone inside or outside the organization has to take responsibility for operating this platform; this is the purpose of platform ops.
Platform ops is the set of activities that creates and sustains an application platform infrastructure. This platform enables the work of one or more development teams that use DevOps practices to build, deploy and operate microservices. Platform ops activities are delivered by a platform team that must include both application development skills and expertise in the chosen cloud platform, whether cloud-hosted or on-premises.
The platform team must deliver a cloud-based platform that supports development, deployment and the operation of multiple independent microservices by multiple autonomous service delivery teams, as shown in Figure 2.
The platform team must think of the microservice platform as a product; its customers are the teams developing and operating microservices.
Platform ops activities must be decoupled from service DevOps to ensure agility. A service delivery team should control the release and management of their services(s). Platform ops activities, such as platform updates, platform optimization and deployment of additional capabilities, must be planned to avoid direct impact on the services the platform supports (see also "Use These Three Best Practices to Power Your Microservice Adoption").
The platform for managing microservices must provide cloud characteristics to the service teams (see the section "Why Do You Need a Cloud Platform for Microservices" for more details). Consider how decoupled a service delivery team is from the platform ops activities of a typical aPaaS public cloud service, such as Amazon Web Services (AWS) Elastic Beanstalk, Google App Engine, Microsoft Azure App Service or Salesforce Heroku. Traditional operations activities such as OS-level monitoring, maintenance and patching, as well as virtual server provisioning and hardware maintenance, are completely hidden on a day-to-day basis.
Using a cloud service provider (CSP) outsources some of the platform ops' responsibility, but never all of it, because no CSP yet provides a fully integrated and complete set of microservice infrastructure capabilities. How much platform ops can be outsourced depends on the requirements of the service DevOps teams and the type of platform, which is the subject of this comparison assessment. Using a CSP also helps improve decoupling between service DevOps and platform ops.
If your requirements dictate that you host this platform on your own infrastructure, you must maintain the decoupling of platform ops from service DevOps. Your organization will have to create a platform ops capability, establishing a team with the skills and resources to support the demands of their customers — the service DevOps teams. Establishing this platform team will require collaboration between application delivery and I&O, and should also embrace DevOps practices (also see "DevOps — Eight Simple Steps to Get It Right").